January 26, 2026
LLM Inference Optimization: Data-Level Techniques
Exploring batching strategies, KV cache management, and speculative decoding for production LLM serving.
This post focuses on data-level optimizations, the first major layer of practical techniques for improving large language model inference. These methods target how requests, tokens, and intermediate state are handled at runtime. Because they directly affect GPU utilization and memory behavior, they often deliver the largest real-world gains in throughput and latency.
We cover three core techniques:
- Batching strategies, with an emphasis on continuous batching
- The KV cache and how modern systems manage its memory footprint
- Speculative decoding, which reduces end-to-end latency using a fast auxiliary model
Batching: From Static to Continuous
Batching is one of the most effective ways to increase throughput on GPUs. By processing multiple requests in parallel, we amortize kernel launches and better utilize hardware parallelism. However, large language models are autoregressive. Each token depends on all previously generated tokens. This property makes naive batching inefficient.
Static batching
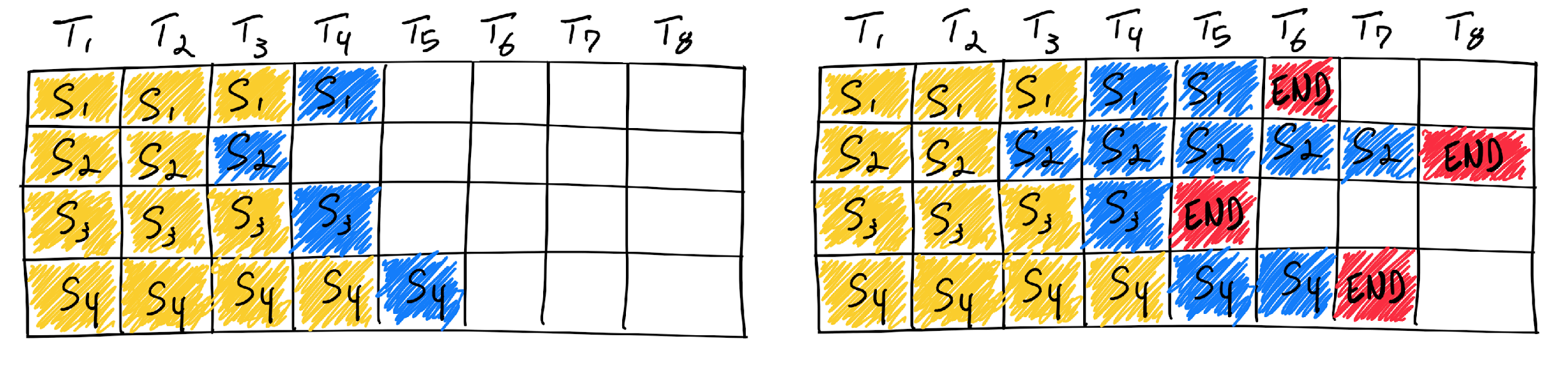
In a traditional static batching setup, the inference server waits until it has collected a fixed number of requests before beginning generation. All requests in the batch proceed token by token in lockstep.
This creates two major inefficiencies:
- Arrival latency: Requests must wait until the batch is full before any computation begins.
- Tail latency from variable sequence lengths: If one request generates a long output, all other requests must wait until it finishes. During this time, many GPU threads sit idle.
These effects compound, leading to poor GPU utilization and unpredictable latency under real traffic.
Continuous batching
Continuous batching addresses these issues by making batching dynamic rather than fixed. Instead of waiting for a full batch, the system immediately admits new requests as GPU capacity becomes available. When a request finishes generating its output, it is removed from the batch and replaced by a new incoming request. Generation proceeds continuously rather than in discrete batch steps. This approach was popularized by systems such as vLLM and has become standard in modern inference servers.
Key benefits:
- High GPU utilization even with heterogeneous request lengths
- Lower average and tail latency
- Robustness to bursty or irregular traffic patterns
Reported throughput improvements over static batching can exceed an order of magnitude in realistic workloads, especially at higher concurrency.
Comparison
| Strategy | Description | Pros | Cons |
|---|---|---|---|
| Static batching | Fixed-size batch processed together until all sequences finish | Simple to implement | High latency, poor GPU utilization, sensitive to request timing |
| Continuous batching | Requests enter and leave the batch dynamically | High throughput, low latency, efficient GPU usage | More complex scheduling and memory management |
The KV Cache
To understand the next optimization, we need to look inside the Transformer during decoding. At token position n, self-attention requires access to all keys and values from positions 1..n-1. Recomputing these at every step would be prohibitively expensive.
What the KV cache stores
The KV cache stores the key and value tensors produced by each attention layer for all previously generated tokens. During decoding, the model only computes the query for the new token and reuses the cached keys and values. This reduces the per-token computation from quadratic to linear in sequence length and is essential for practical inference.
The memory problem
While the KV cache is computationally efficient, it consumes a large amount of GPU memory:
- Memory grows linearly with sequence length
- Memory scales with number of layers, heads, and batch size
- Long-context workloads can become KV-bound rather than compute-bound
As context lengths increase, KV cache management becomes a primary bottleneck.
Techniques for managing KV cache memory
PagedAttention
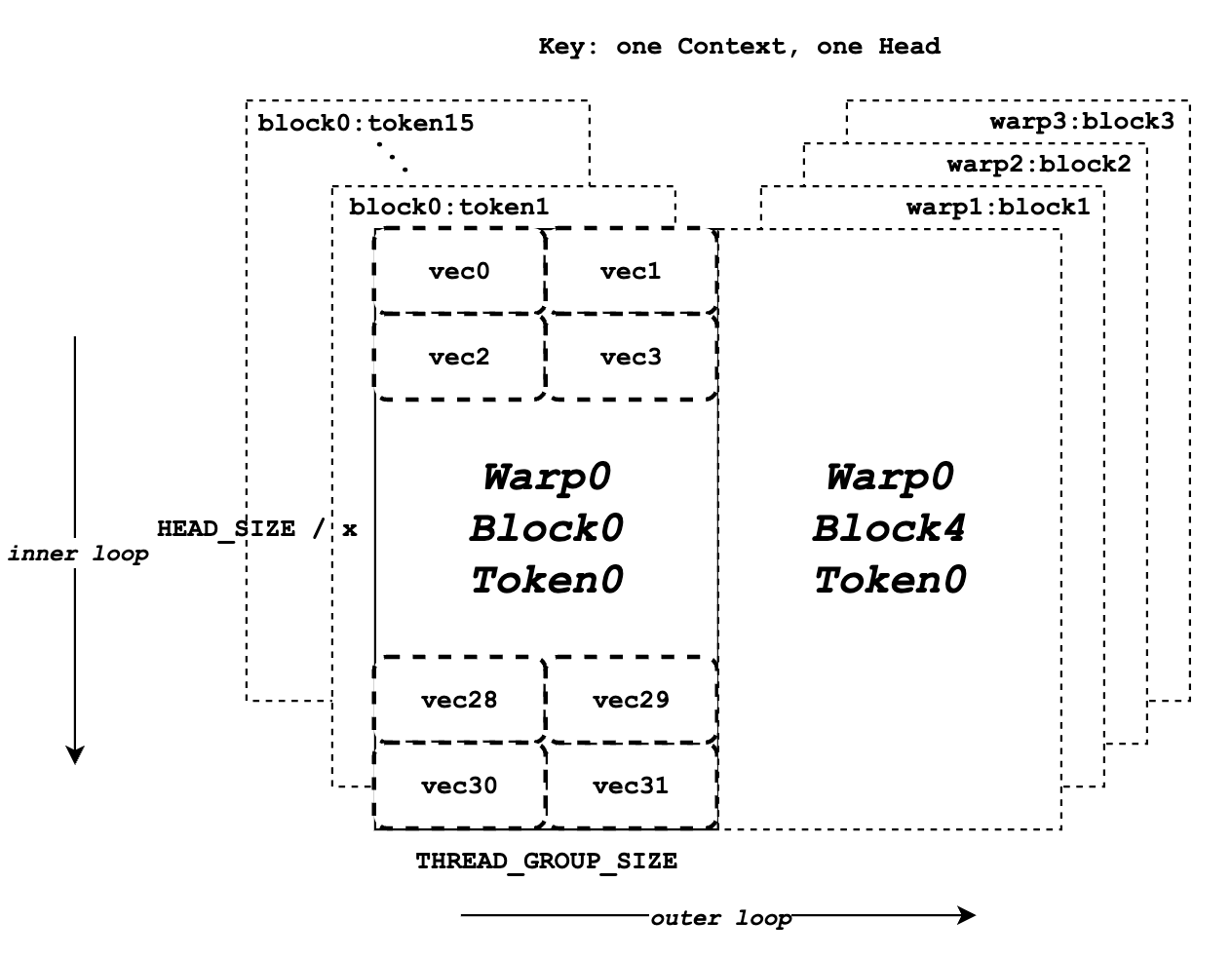
PagedAttention, introduced in vLLM, manages the KV cache using fixed-size memory blocks rather than contiguous allocations.
This design is similar to virtual memory systems:
- KV cache blocks can be allocated and freed independently
- Fragmentation is minimized
- Memory can be shared more efficiently across requests
PagedAttention enables continuous batching to work reliably at high concurrency without running into memory exhaustion.
Eviction policies
When memory pressure is high, some systems evict KV cache entries. Simple policies like FIFO are easy to implement but suboptimal.
More advanced approaches attempt to:
- Preserve tokens that are likely to be attended to again
- Adapt eviction decisions based on observed attention patterns
This area remains active research, especially for very long context windows.
KV cache quantization
KV tensors do not always require full FP16 precision. Reducing precision to INT8 or similar formats can significantly reduce memory usage with minimal quality impact.
KV quantization is typically combined with other techniques and is discussed more deeply in model-level optimization.
Speculative Decoding: Reducing Perceived Latency
Speculative decoding is a technique for accelerating generation without changing the output distribution of the target model.
How it works
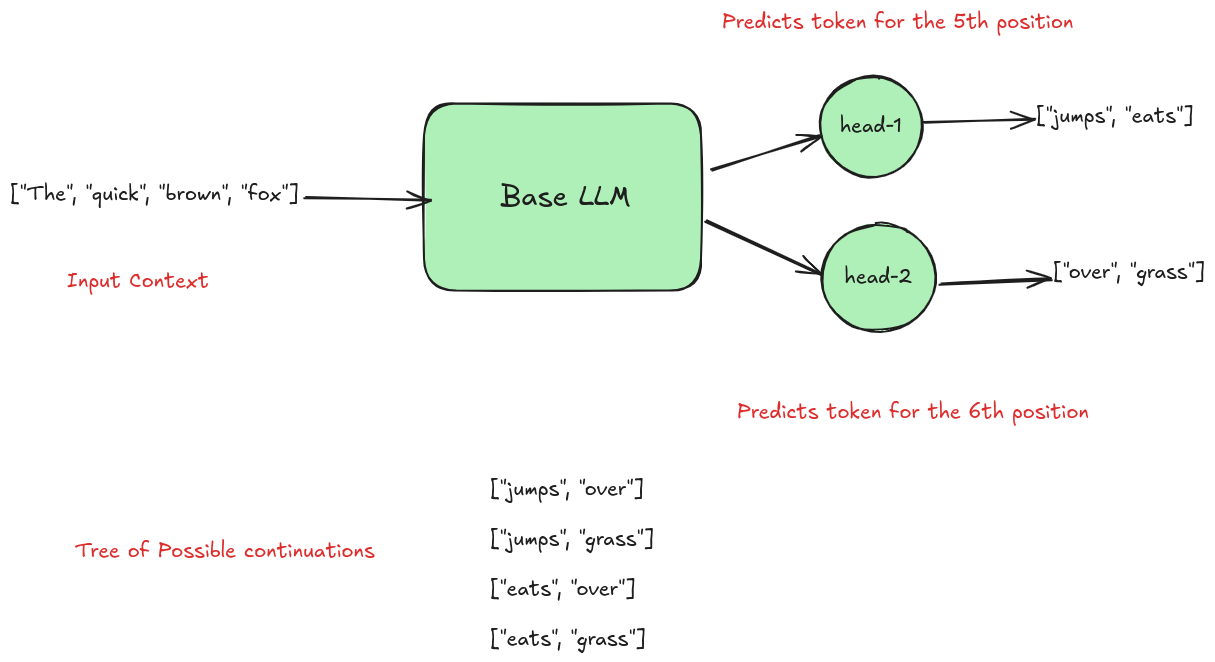
The system uses two models:
- A draft model that is small and fast
- A target model that is large and accurate
The draft model generates several tokens ahead speculatively. These tokens are then verified by the target model in a single forward pass.
- If the target model agrees with the draft tokens, they are accepted
- If it disagrees, the speculative tokens are discarded and decoding resumes normally
In effect, multiple tokens can be generated at the cost of one target-model step.
Why it works
Although the draft model is less accurate, it often predicts common or high-probability tokens correctly. This allows the target model to skip redundant work and focus on harder decisions. The result is lower end-to-end latency without degrading output quality.
Empirical results typically show 2x to 3x speedups, depending on how closely the draft model matches the target model and the number of speculative tokens used.
Conclusion
Data-level optimizations are often the highest-leverage techniques for improving LLM inference performance.
- Continuous batching maximizes GPU utilization under real traffic
- KV cache optimizations enable long contexts and high concurrency
- Speculative decoding reduces latency without sacrificing quality
These methods form the backbone of production-grade LLM serving systems today.