February 12, 2026
LLM Inference Optimization: Model-Level Techniques
A deep dive into quantization, pruning, knowledge distillation, and FlashAttention for efficient model compression.
Welcome to the third installment of our series on LLM inference optimization. Having covered data-level strategies in our previous post, we now turn our attention to the model itself. Model-level optimizations are powerful techniques that modify the neural network's architecture or weights to make it smaller, faster, and more memory-efficient without significantly compromising its performance.
In this post, we will explore three foundational pillars of model compression:
- Quantization, the art of reducing numerical precision
- Pruning, the science of removing redundant parameters
- Knowledge Distillation, the process of training a smaller model to mimic a larger one
We will also revisit the architectural innovation of FlashAttention as a key model-level improvement.
1. Quantization
Quantization is one of the most effective and widely used model compression techniques. At its core, quantization involves reducing the number of bits used to represent a model's weights and, in some cases, its activations.
Most deep learning models are trained using 32-bit floating-point numbers (FP32), which offer a wide dynamic range and high precision. However, this level of precision is often not necessary for inference. By converting these weights to lower-precision formats like 16-bit floats (FP16/BF16) or even 8-bit or 4-bit integers (INT8/INT4), we can achieve substantial benefits.
As explained in a comprehensive visual guide by Maarten Grootendorst, a 70-billion parameter model in its native FP32 format would require a staggering 280GB of memory just to load. Quantizing this model to INT8 could reduce its size by a factor of four, to just 70GB, making it accessible on a much wider range of hardware.
Symmetric vs. Asymmetric Quantization
The process of mapping a high-precision value to a lower-precision one is not trivial. The two primary methods for this linear mapping are symmetric and asymmetric quantization.
- Symmetric Quantization: This method maps the range of floating-point values to a symmetric range around zero in the quantized space. A common approach is absolute maximum (absmax) quantization, where the scaling factor is determined by the maximum absolute value in the tensor. This is simpler and often faster computationally.
- Asymmetric Quantization: This method maps the exact minimum and maximum values from the float range to the quantized range, introducing a "zero-point" offset. This can provide a better fit for weight distributions that are not centered around zero, potentially preserving more accuracy.
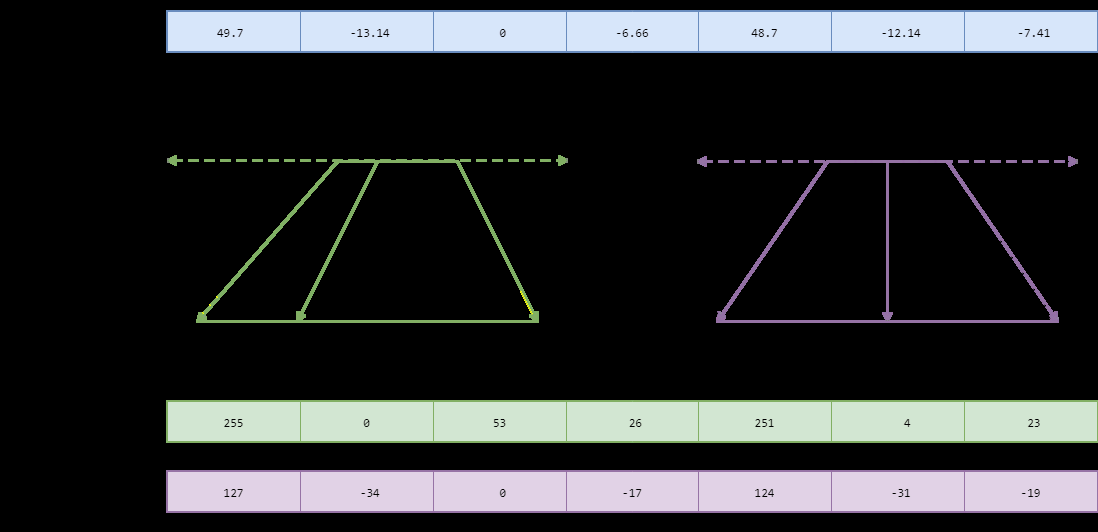
PTQ vs. QAT
There are two main approaches to applying quantization:
- Post-Training Quantization (PTQ): This is the simplest method, where a pre-trained model is quantized after training is complete. It's fast and doesn't require access to the original training data. However, it can sometimes lead to a noticeable drop in accuracy, especially at very low bit-widths (e.g., INT4).
- Quantization-Aware Training (QAT): In this approach, the quantization process is simulated during the training or fine-tuning phase. The model learns to adapt to the reduced precision, which often results in significantly better accuracy compared to PTQ. The trade-off is that QAT is more complex and requires a representative dataset and additional training cycles.
2. Pruning
Neural networks, especially large ones, are notoriously over-parameterized. Many of their weights are redundant or contribute very little to the final output. Pruning is the process of identifying and removing these non-essential parameters. The goal is to create a smaller, sparser model that is computationally cheaper while retaining most of the original model's accuracy.
Pruning Techniques
As illustrated in research on filter pruning algorithms, pruning techniques can be broadly categorized into two types: unstructured and structured.
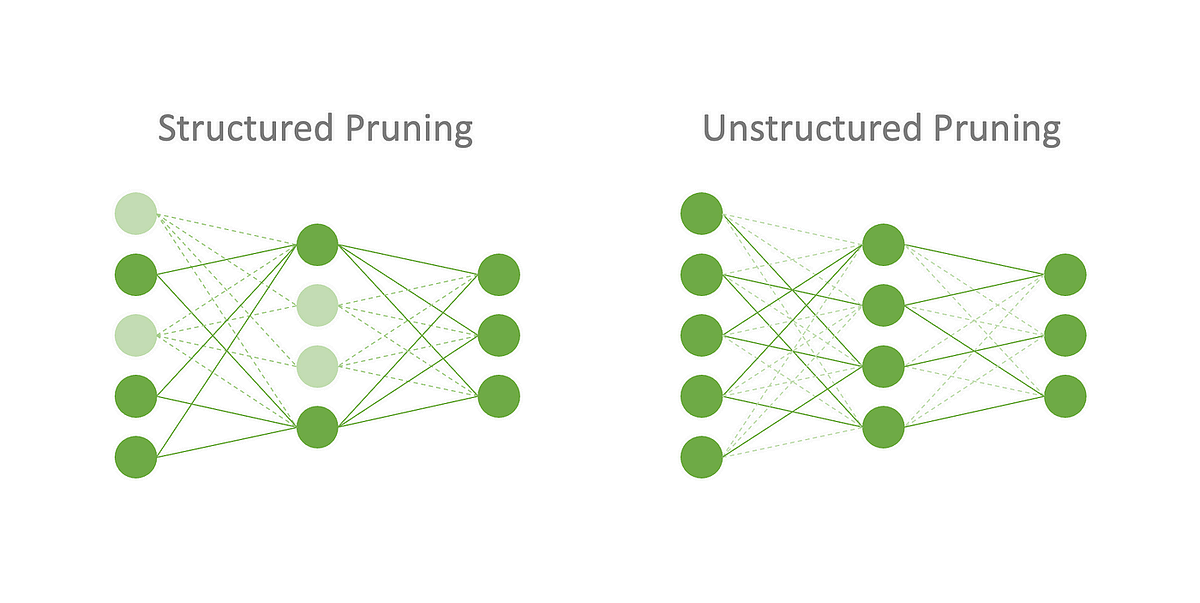
- Unstructured Pruning: This involves removing individual weights based on their magnitude or importance. While it offers the highest flexibility and can achieve very high sparsity levels, the resulting irregular sparse matrices are difficult to accelerate on standard hardware like GPUs, which are optimized for dense matrix operations.
- Structured Pruning: This technique removes entire groups of parameters, such as complete filters, channels, or even layers. This approach is much more hardware-friendly, as it results in smaller, dense matrices that can be processed efficiently. This makes structured pruning a more practical choice for real-world deployment.
3. Knowledge Distillation
Knowledge Distillation is a model compression technique where a small "student" model is trained to mimic the behavior of a larger, more powerful "teacher" model. Instead of training the student solely on the ground-truth labels (hard targets), it is also trained to match the output probability distribution of the teacher model (soft targets).
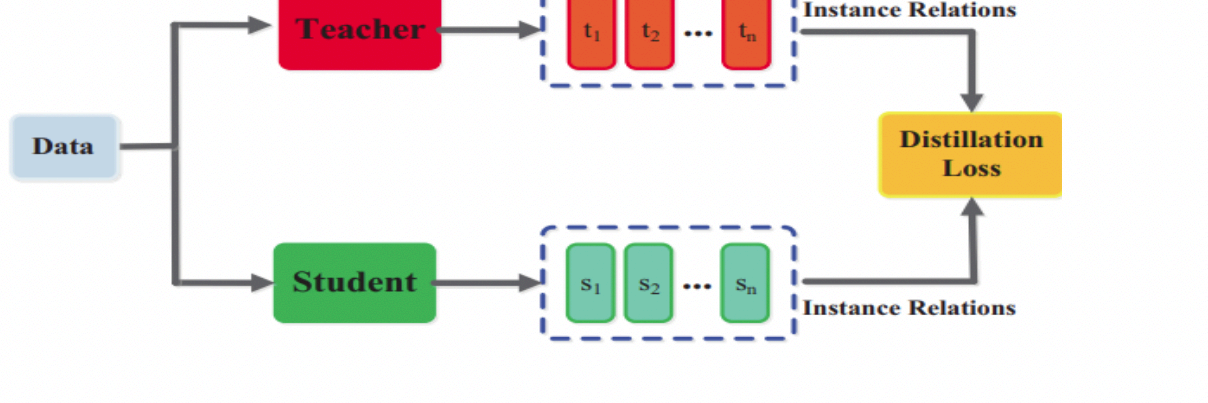
The soft targets from the teacher provide much richer information than the hard labels alone. They reveal how the teacher model "thinks" and generalizes across different classes. By learning from this richer signal, the student model can often achieve significantly higher accuracy than if it were trained from scratch on the same data, effectively compressing the "knowledge" of the larger model into a much smaller footprint.
4. FlashAttention
Beyond compressing existing models, another avenue for model-level optimization is to innovate on the architecture itself. As we discussed in our data-level post, the attention mechanism is a major bottleneck in Transformer models.
FlashAttention is a groundbreaking architectural change that reorders the attention computation to be I/O-aware, significantly reducing the number of memory reads and writes between the GPU's high-bandwidth memory (HBM) and its on-chip SRAM.
By using techniques like tiling and kernel fusion, FlashAttention avoids materializing the large intermediate attention matrix, which is the primary source of memory inefficiency in standard attention. This leads to dramatic speedups and a much smaller memory footprint, allowing for longer context lengths and faster training and inference.
Conclusion
Model-level optimizations are a critical component of the LLM inference stack. Techniques like quantization, pruning, and knowledge distillation allow us to shrink massive models into more manageable forms, while architectural innovations like FlashAttention fundamentally improve their efficiency.
By combining these strategies, practitioners can build models that are not only powerful but also practical to deploy in real-world, resource-constrained environments.