February 4, 2026
Object Storage for Vector Search at Scale
A deep dive into the cost curve, caching, and tradeoffs behind S3-first vector search at scale.
The Pattern
This story plays out all the time.
A team ships an AI feature. They need vector search, so they grab Pinecone, Weaviate, Qdrant, whatever has decent docs and gets them to production fastest. Totally reasonable. Ship first, optimize later.
Six months in, they're sitting on 50 million vectors. The bill stings a little, but it's manageable. The team has bigger fish to fry.
Twelve months in, it's 500 million vectors spread across thousands of tenants. The bill now shows up in exec reviews. Finance starts asking pointed questions about unit economics.
Eighteen months in, they've crossed a billion vectors. Engineers are bin-packing tenants onto shards just to keep costs from spiraling. Noisy neighbor issues are a regular thing. Index rebuilds happen at 3 AM to avoid hitting users. That early decision (the one that got them to market) has become a constant source of operational headaches.
None of this is a planning failure. It's just what happens when teams follow a perfectly sensible strategy: move fast early, pay down technical debt later. The real question is what "paying down that debt" actually looks like in practice.
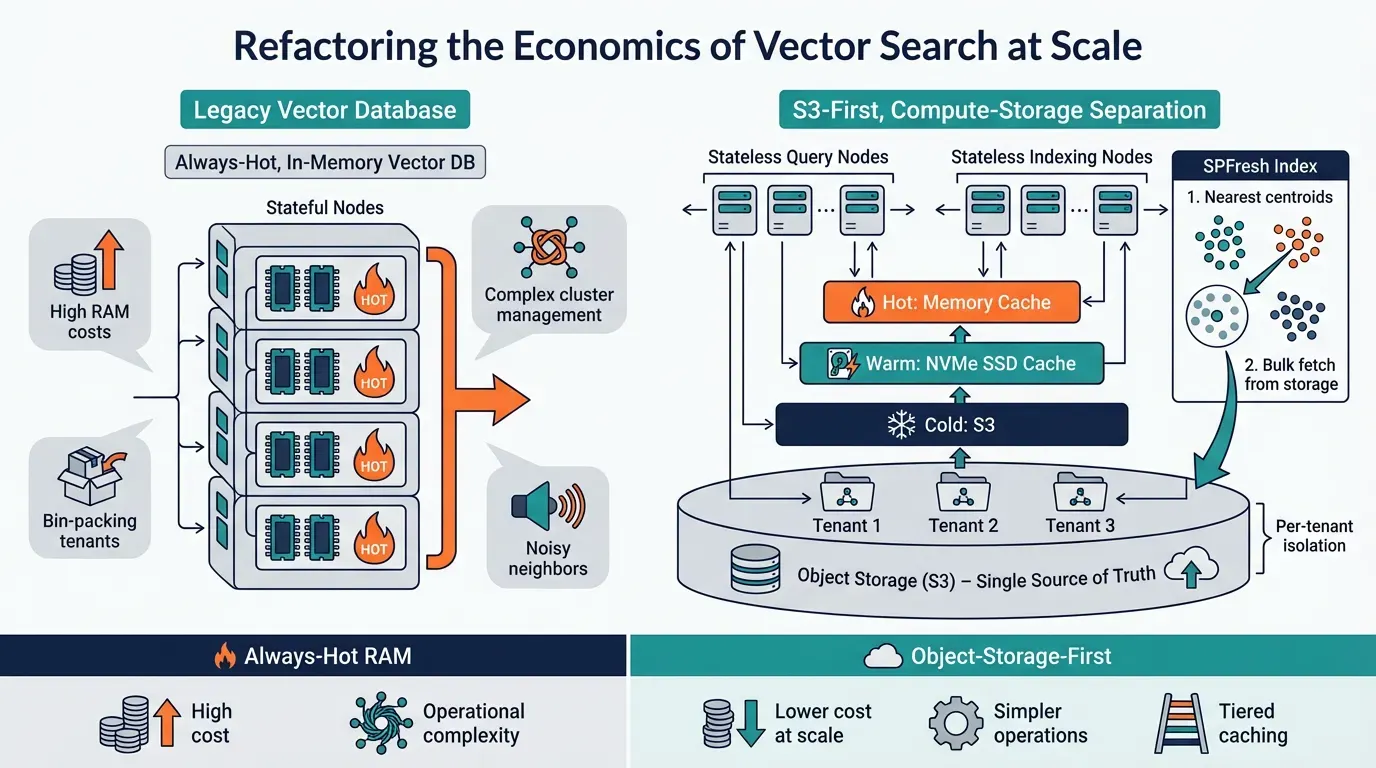
The Core Economics Problem
Most managed vector databases are built on a simple assumption: keep everything hot in memory.
This is explicit in their documentation. Pinecone's pod-based indexes store vectors in RAM, a p1 pod holds ~1M vectors at 768 dimensions, while s1 pods trade some latency for 5M vectors per pod. Weaviate's docs state directly: "The HNSW vector index is the primary driver of memory usage" and recommend keeping vectors in memory for performance. Qdrant defaults to in-memory storage, noting it "has the highest speed since disk access is required only for persistence."
This makes sense if you're optimizing for latency above all else. Memory is fast. Disk is slow. Network is slower. If every query needs sub-10ms response times and you can afford to pay for it, keeping indexes in RAM is the right call.
But here's what that assumption costs you at scale:
- You pay for peak capacity, not actual usage. Most tenants have long tails of rarely-accessed data. You're keeping vectors warm that get queried once a month.
- Multi-tenancy becomes an operational nightmare. You need sophisticated bin-packing to avoid wasting memory, which introduces blast radius concerns and operational complexity.
- Spiky workloads are expensive. Onboarding bursts, re-indexing events, seasonal traffic: all require headroom you're paying for 24/7.
The fundamental insight behind turbopuffer is that not all vectors need to be hot all the time. If you accept some latency for cold queries, you can build on object storage and dramatically change the cost curve.
What Makes turbopuffer Architecturally Different
turbopuffer is built from first principles around compute-storage separation with object storage (S3) as the single source of truth (see guarantees). This is a genuine architectural departure, not just a deployment variation. Here's why it matters.
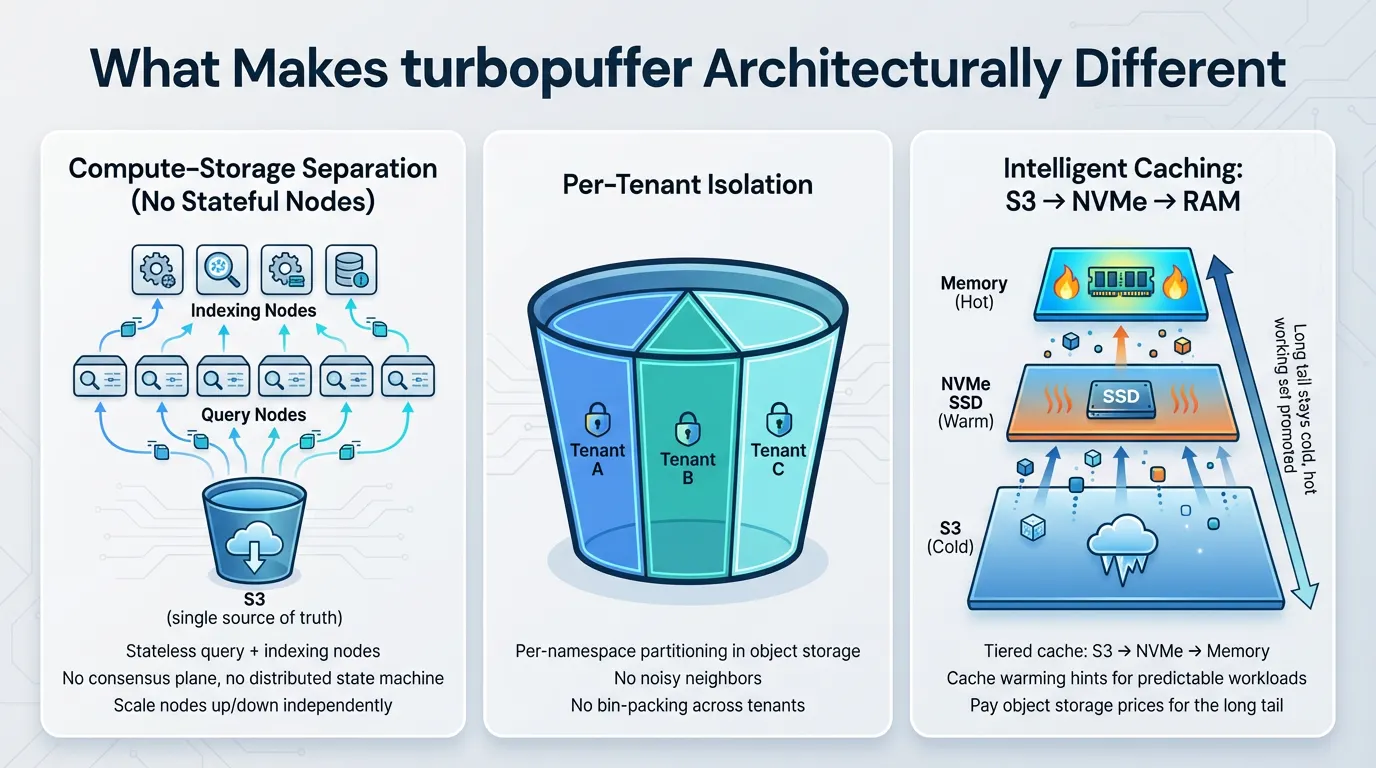
No Stateful Nodes to Manage
Object storage serves as the sole stateful dependency in the turbopuffer architecture. There is no need for a separate consensus plane, no requirement for a distributed state machine, and no complex failover logic to configure or maintain. Both query nodes and indexing nodes are designed to be completely stateless, which means they can be scaled up or down independently without coordination overhead or state migration concerns.
This architectural simplicity delivers real, tangible operational value in production environments. With fewer moving parts in the system, there are correspondingly fewer components that can fail or require intervention at 2am when you're on call.
Per-Tenant Isolation Built Into the Architecture
Since data is stored in object storage with per-namespace partitioning at the foundational level, tenant isolation becomes an inherent property of the system rather than something that needs to be actively managed or engineered around. There's no need to engage in complex bin-packing strategies to efficiently utilize resources. There are no noisy neighbor problems where one tenant's workload inadvertently impacts another tenant's performance. The challenge of scaling to handle 100+ billion vectors distributed across millions of individual tenants transforms from a complex cluster management and orchestration problem into a straightforward exercise in understanding and optimizing object storage economics.
Intelligent Caching Strategy, Not Always-Hot Data
The architecture implements a sophisticated tiered cache hierarchy that moves data through multiple storage layers based on the access pattern: S3 → NVMe SSD → Memory
Data that is accessed frequently gets automatically promoted up through the storage hierarchy stack, moving closer to the compute layer for faster access. Meanwhile, the long tail of infrequently accessed data remains in its cold state within object storage, incurring minimal cost. The system also supports cache warming hints, which allow you to preemptively heat up data for predictable access patterns before queries actually arrive.
This tiering strategy represents the fundamental economic lever that makes the architecture cost-effective at scale: you're paying object storage prices (which are very low) for the vast majority of your data volume, while only paying premium memory prices for the actively hot working set that's being queried regularly.
The Index: Why SPFresh Matters
Most vector databases use HNSW (Hierarchical Navigable Small Worlds) or DiskANN: graph-based indexes that work by traversing edges between related vectors (HNSW vs DiskANN).
This is the industry standard. Weaviate uses HNSW and notes it's "very fast, memory efficient" but warns that "memory requirements of an HNSW index can quickly become a bottleneck" as collections grow (Weaviate vector index). Qdrant also uses HNSW and explicitly notes that storing the index on disk "may require IO operations" during graph traversal, recommending on-disk storage "only when RAM is severely constrained" (Qdrant overview).
These indexes are excellent on local SSD. Each hop in the graph is a random read, and SSDs handle random reads well (discussion).
But graph traversal is a terrible fit for object storage. Each hop would be a round-trip to S3. A single query might require dozens of fetches. Latency would be measured in seconds, not milliseconds.
turbopuffer uses SPFresh, a centroid-based index published at SOSP '23 (paper). The core insight: instead of traversing a graph, cluster vectors around centroids and do a two-step lookup:
- Find the nearest centroids (small index, can live in memory)
- Search within those clusters (single bulk read from storage)
This reduces object storage round-trips to a maximum of 2 per query, even for cold data (architecture).
The other critical property: SPFresh is self-balancing. As data changes, clusters split and merge automatically. No global rebuilds required (native filtering). This matters enormously for operational simplicity: you're not scheduling index maintenance windows or dealing with quality degradation between rebuilds.
The Recall Question
Here's something that trips up teams new to vector search: ANN indexes can return garbage results if misconfigured (comparing indexes).
Unlike a B-tree, where wrong results are a bug, ANN indexes are explicitly approximate. The tradeoff between speed and accuracy is tunable. Get it wrong and you'll have fast queries that return irrelevant results.
The key metric is Recall@k: what percentage of the true nearest neighbors appear in your top k results (paper).
turbopuffer auto-tunes for 90-100% recall and continuously monitors production queries (vector docs). This is the right default. Most teams shouldn't be hand-tuning index parameters.
Filtered search is where things get tricky. Graph indexes can fail catastrophically under heavy filtering. If your filter removes 90% of vectors, you've broken the graph's connectivity, and recall can drop below 40% (techniques overview).
turbopuffer builds filter-aware indexes that maintain recall even under aggressive metadata filtering (architecture). If your use case involves heavy filtering (and most real-world use cases do), this matters a lot.
Hybrid Search: The Right Default for Production
Pure vector search has a blind spot: exact matches.
If a user searches for "TS-01" (a ticket ID) or "john.smith@company.com", semantic similarity might not surface the exact match. The embedding might be close to other identifiers, but not exactly right.
turbopuffer supports hybrid search: dense vectors + BM25 sparse retrieval. Results are merged via Reciprocal Rank Fusion (RRF), which handles the fact that vector similarity scores and BM25 scores are on different scales (OpenSearch writeup, Vertex AI overview).
For production systems, hybrid search is almost always the right choice. Semantic search for intent, lexical search for precision (Elastic overview).
The Tradeoffs (Because There Are Always Tradeoffs)
Be clear about what you're giving up with an object-storage-first architecture.
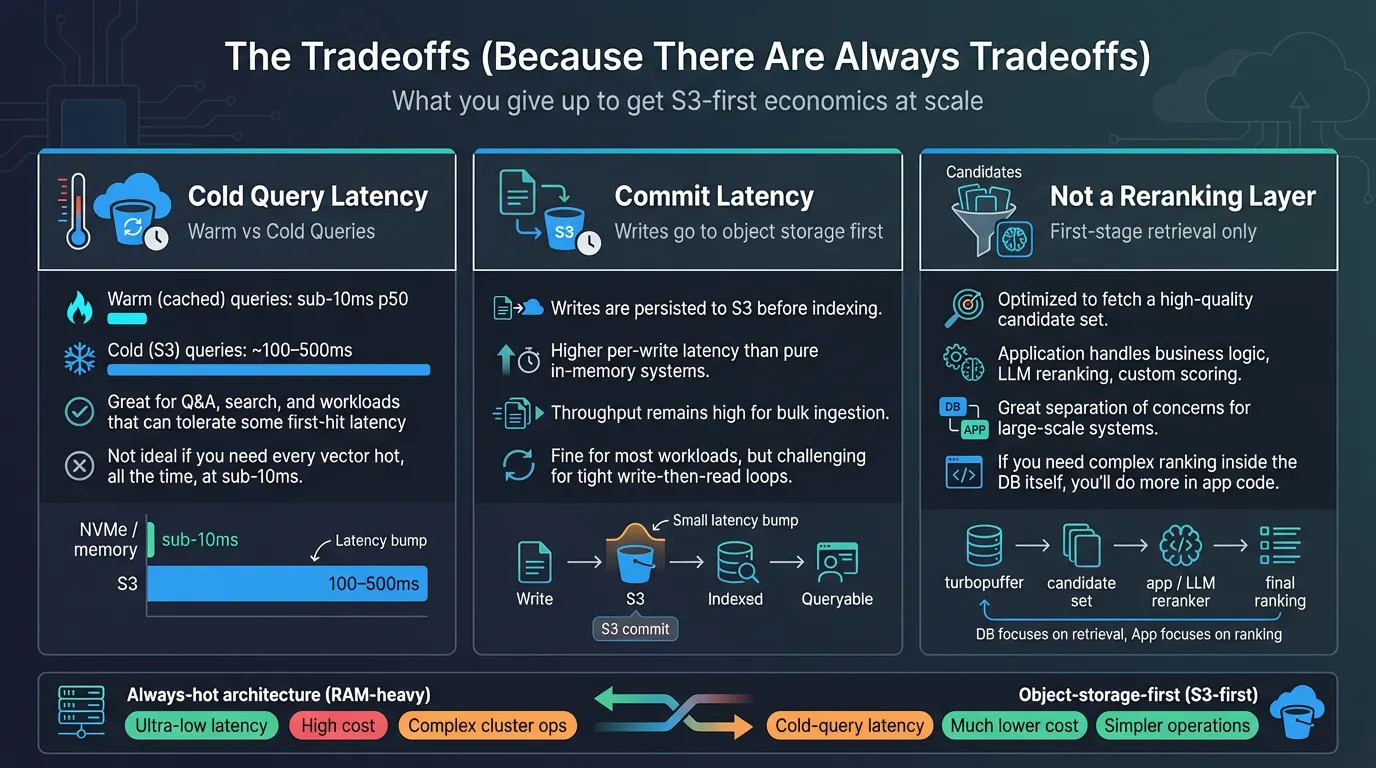
Cold Query Latency
Warm queries (cached data) are fast: sub-10ms p50. Cold queries hit object storage and can take 100-500ms (architecture).
For many workloads, this is fine. Search results don't need to be as fast as autocomplete. Q&A features are already waiting on LLM inference.
But if your use case requires consistent sub-10ms latency on the first query to any vector, even vectors that haven't been accessed in months, an always-hot architecture might be the right call, despite the cost.
Commit Latency
Writes go to object storage before being indexed. Individual write latency is higher than in-memory systems, though throughput remains high.
For most use cases, this doesn't matter: you're not trying to query a document milliseconds after creating it. But if your application requires synchronous write-then-read patterns at high frequency, you'll need to design around this.
Not a Reranking Layer
turbopuffer is optimized for first-stage retrieval: generate a high-quality candidate set, then let your application handle complex business logic, LLM reranking, or custom scoring.
This is the right separation of concerns for most architectures. But if you need the database itself to handle sophisticated ranking logic, you'll be doing that in application code.
When to Consider turbopuffer
Based on the comprehensive pattern and architectural considerations described above, turbopuffer makes strong technical and economic sense when your system exhibits the following characteristics:
- You're operating at significant scale (managing hundreds of millions to billions of vectors)
- Cost is becoming a meaningful concern (the bill has become a regular topic in budget reviews)
- You have multi-tenant workloads (serving thousands to millions of distinct tenants)
- Your data exhibits a long tail distribution (most vectors aren't queried frequently)
- Operational simplicity matters (you'd prefer not to manage index rebuilds and cluster rebalancing)
Conversely, it's probably not the optimal choice if:
- You're at an early stage and need to ship rapidly (use something simpler to get started)
- Your entire corpus must remain hot (strict latency requirements on all data, all the time)
- You have very small scale requirements (under ~10 million vectors)
Migration: Doing It Right
If you're switching from one vector database to another, treat this as an opportunity to modernize your infrastructure rather than a lift-and-shift.
Full re-indexing is superior to incremental migration. Rebuild your entire corpus cleanly in the new system.
Upgrade your embeddings during migration. If you've been considering a better embedding model or reducing dimensions, this is the ideal time.
Simplify your architecture. Remove legacy sharding strategies, routing logic, and manual bin-packing code. Let the new system handle tenant isolation natively.
Validate with dual reads. Run both systems in parallel during cutover, comparing results and latency before switching production traffic.
Keep a vector lake as backup. Store a complete copy of embeddings in your own S3. This reduces future switching costs and provides a recovery option.
The Bottom Line
Vector search infrastructure is at an inflection point. The first generation of managed vector databases optimized for simplicity and speed-to-market. That was the right call for an emerging category.
But as AI workloads scale, the economics of always-hot architectures are becoming untenable for many teams. Object-storage-first approaches like turbopuffer represent a fundamentally different set of tradeoffs: accept some cold query latency in exchange for dramatically better economics and simpler operations at scale.
Notable companies already operating at this scale on turbopuffer include Anthropic, Cursor, Ramp, Linear, and others.
The key question isn't "which database is best." It's "which tradeoffs match your workload?" If you're experiencing the pain described above—cost pressure, operational complexity, multi-tenant headaches—it's worth running the numbers on what an object-storage-first architecture could look like for your system.